Secure HPC Batch Processing with tiCrypt and Slurm

High-performance computing clusters are shared environments by nature. Dozens or hundreds of researchers submit jobs to the same nodes, access the same file systems, and rely on the same scheduler. That model works well for performance but creates serious challenges when the job or the data is sensitive.
The scope of what counts as sensitive has expanded. Controlled unclassified information (CUI), protected health information (PHI), and export-controlled research have long required special handling. Now AI workflows introduce new categories: training datasets contain proprietary or licensed content that cannot be exposed to other tenants or administrators. Trained models are intellectual property, not disposable artifacts. The training code itself may encode trade secrets, novel architectures, or fine-tuning techniques that are as valuable as the data they process. On a shared HPC cluster, all of these are visible to system administrators and potentially to other users.
This article explains how tiCrypt integrates with Slurm through a dual-scheduler architecture that separates resource allocation from secure execution.
The Problem: HPC Was Not Designed for Data Security
Traditional HPC clusters treat security as a perimeter concern. A firewall protects the cluster boundary, data may be encrypted at rest, and users authenticate with passwords. Once inside, the security model is thin:
- OS user accounts control access: Every user has an account on every node. System administrators have root access to all data on all nodes.
- Password-based authentication: Passwords are shared secrets that can be intercepted, reused, or phished. A single compromised password grants full access to that user's data and jobs.
- No job isolation: Slurm jobs run as OS processes on shared nodes. A compromised job can access the memory, files, and network traffic of other jobs on the same node.
- No code protection: Job scripts and binaries are visible to administrators and, in many configurations, to other users.
- Infrastructure-level access: System administrators can read any file, inspect any running process, and intercept any network communication on the cluster.
These are not hypothetical risks. They are structural properties of how Slurm clusters operate. Encryption at rest does not help when the data must be decrypted for computation. MFA does not help when the authentication layer still relies on shared secrets that the infrastructure can observe. Firewalls do not help when the threat is internal.
For regulated workloads, these gaps are disqualifying. NIST SP 800-171 requires access control enforcement beyond OS-level permissions (3.1.1, 3.1.2), encryption of CUI in transit and at rest (3.13.8, 3.13.11), and audit logging of all access (3.3.1, 3.3.2). A standard HPC cluster cannot satisfy these controls without fundamental architectural changes.
How tiCrypt Secures HPC Workloads
tiCrypt protects data and computation even when the infrastructure itself is untrusted. All computation occurs within secure virtual machines. The security model covers encryption, authentication, network access, and drive protection.
The control channel between the user and the VM runs over WebSockets into the tiCrypt backend. All communication is encrypted and authenticated with digital signatures. The backend and system administrators cannot read or intercept the contents. There is no central credential store to compromise and no shared secret crosses the network.
VM drives are encrypted within the VM using LUKS. Encryption keys are provided by the data owner, not the infrastructure. Administrators never possess them, so drive contents are inaccessible outside the VM even if the underlying storage is compromised. VMs are ephemeral: created for the job and destroyed on completion, with the encryption key discarded so the drive cannot be recovered.
VMs do not have general TCP access. All traffic is tunneled via port 22. The tunnel originates at the user's access point and terminates inside the VM, and opening it requires digital signature proof of identity. VMs have no general internet connectivity. Only access to licensing servers (when explicitly allowed) and the tiCrypt backend is permitted. Outbound rules are enforced centrally by the tiCrypt backend acting as the sole gateway.
Each secure VM is managed by ticrypt-vm-controller, which acts as the guardian of the VM on behalf of the user. It handles provisioning, network setup, Slurm node registration, and teardown. It validates all incoming connections and rejects any that cannot provide a valid digital signature.
All secure VMs operate on a flat Layer 2 network built on OpenVSwitch (br-secure), VLAN-isolated from all other traffic. No VM traffic exits through the compute hosts. VMs from different projects cannot reach each other.
These properties apply to every Slurm job that runs through tiCrypt. The dual Slurm architecture described below enforces them without requiring changes to user workflows.
The Dual Slurm Architecture
tiCrypt splits the scheduler into two layers that communicate through the tiCrypt backend. Each layer has a specific, limited role.
Global Slurm
Global Slurm is the standard cluster-wide scheduler. It manages hardware resources (CPUs, memory, nodes) and enforces fairness across all projects and users. Global Slurm:
- Allocates nodes and resources based on job requests.
- Enforces quotas, priorities, and partition policies.
- Runs under a service account with no access to user data.
- Sees only resource requests, not job scripts, data paths, or application code.
Global Slurm is the only component that interacts with the physical cluster hardware. From its perspective, every job is a request for CPUs, memory, and time. Job scripts, environment variables, and data paths all remain within the secure enclave.
Local Slurm
Local Slurm runs inside tiCrypt's secure enclave, within a VM controlled by the project. It is a full Slurm instance with its own controller (slurmctld), node daemons (slurmd), and job queue. Local Slurm:
- Accepts job submissions from users through the in-browser terminal or RDP session.
- Has full visibility into job scripts, data, and execution.
- Manages compute nodes that are themselves secure VMs.
- Runs entirely within the encrypted enclave, invisible to Global Slurm and to system administrators.
tiCrypt eliminates OS user accounts on compute nodes entirely. The only account on each node is the service account used by ticrypt-host-controller to manage VMs. Users authenticate with their private keys through the tiCrypt frontend.
Users interact only with Local Slurm using standard commands (sbatch, srun, squeue, sacct). The dual-layer architecture is transparent to the end user.
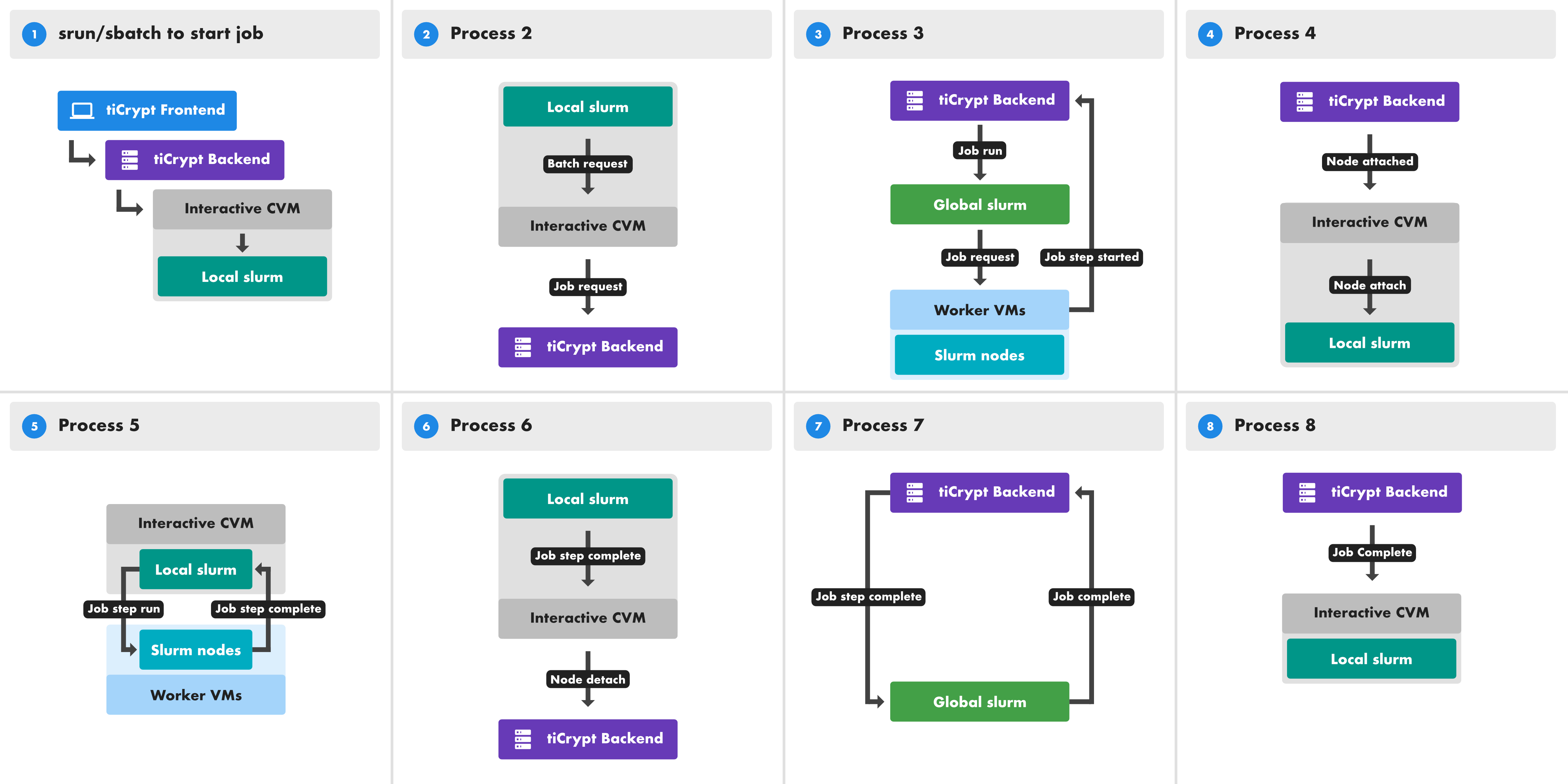
How a Job Executes
When a user submits a job to Local Slurm, the following sequence occurs:
- The user submits a job to Local Slurm from within a secure VM, specifying resource requirements and the code to execute.
- Local Slurm intercepts the job (using a Lua plugin) and forwards a resource request to
ticrypt-vm-controller. ticrypt-vm-controllersends the resource request to the tiCrypt backend. The request contains only resource specifications (CPUs, memory, time), not job content.- The tiCrypt backend creates a Global Slurm job tagged with the user's account and project.
- Global Slurm schedules the job on one or more compute nodes and starts it.
- On each allocated node,
ticrypt-host-controllerreceives the job and starts a secure VM. The tiCrypt backend is notified to hand each VM over toticrypt-vm-controllerfor provisioning. ticrypt-vm-controllerstartsslurmdon each new VM, incorporating them into the Local Slurm cluster.- The job executes inside the secure VMs under
slurmd. Data is accessed through an encrypted VPN (StrongSwan) that mounts project storage from the controlling VM. - Job output is written to the encrypted project file system.
- When the job finishes,
ticrypt-vm-controlleris notified by the Lua plugin and destroys all VMs associated with the job, removing them from the Local Slurm cluster. - The encrypted drives are wiped and the encryption keys are discarded, making the drive contents unrecoverable.
- The Global Slurm job finishes and the resources are released.
Each job runs in one or more dedicated VMs, each with its own encrypted drive. VMs belonging to the same job communicate over the isolated tiCrypt-controlled network but cannot reach VMs from other jobs or the host OS. Because VMs are destroyed on completion and the encryption keys are discarded with the drives, no job artifacts persist on cluster hardware. All access is logged through tiCrypt's audit system using cryptographically verified identities.
System administrators can manage cluster hardware and Global Slurm policies, but they cannot access job content, data, or results. Encryption keys are derived from user key pairs that the infrastructure never possesses.
Multi-Node Jobs
When a job spans multiple physical nodes, Global Slurm allocates resources across hosts and a secure VM is started on each. Because all VMs share the same br-secure network, VMs participating in a job communicate directly at Layer 2 without routing through the host OS. Multi-node srun steps and MPI workloads operate within the same isolated network. The physical topology is invisible to the job.
Practical Considerations
User Experience
From the researcher's perspective, submitting a Slurm job in tiCrypt is identical to submitting one on a traditional cluster. Standard commands (sbatch, srun, squeue, scancel, sacct) work unchanged. The security mechanisms operate below the application layer.
Performance
Virtualization adds overhead, but for most HPC workloads the cost is modest. The table below summarizes typical performance differences between bare-metal and virtualized execution based on published benchmarks.
| Metric | Bare-Metal | Virtualized (KVM) | Overhead |
|---|---|---|---|
| CPU (integer/floating-point) | Baseline | 0 to 2% | Negligible |
| Memory bandwidth | Baseline | 1 to 5% | Minimal |
| Disk I/O (sequential) | Baseline | 2 to 8% | Low |
| Network throughput (virtio) | Baseline | 5 to 10% | Moderate |
| Network latency | Baseline | 5 to 15% | Moderate |
Sources: IBM Systems performance reports on KVM overhead (2018); University of Wisconsin study on virtualization overhead in scientific workloads (Younge et al., 2011); Cloudzy comparative benchmarks on KVM vs bare-metal (2024).
VM startup adds 20 to 30 seconds per job. For long-running batch jobs this is negligible. For short, interactive workloads it is more noticeable. The tradeoff is full end-to-end encryption, job isolation, administrator exclusion, and compliance with NIST SP 800-171 and CMMC Level 2, capabilities that a bare-metal cluster cannot provide without fundamental architectural changes.
MPI and the Case for Bare-Metal Execution
MPI workloads are sensitive to the latency and bandwidth overhead that virtualization introduces. The hypervisor's virtual network layer adds latency to every message exchange, and even with SR-IOV passthrough for InfiniBand, scheduling jitter from the virtualization layer degrades performance on tightly coupled jobs.
To address this, tiCrypt is developing bare-metal container support for Local Slurm. Instead of launching a VM, the compute node runs an Apptainer/Singularity container that takes exclusive ownership of the entire node. The container uses the same br-secure network bridge, StrongSwan VPN tunnel, and ticrypt-vm-controller registration as a VM. From Local Slurm's perspective, it is indistinguishable from a VM node.
The trade-off: bare-metal containers offer native network performance but provide weaker isolation than full virtualization. The container shares the host kernel. Whole-node allocation, encrypted overlay drives, and network isolation mitigate the exposure, but the attack surface is larger than with a hypervisor boundary.
For details on the design and security considerations, see Bare-Metal Support: Running tiCrypt+Slurm on Physical Hardware.
Scalability
The dual architecture scales with the underlying cluster. Global Slurm manages cluster resources using standard scheduling policies. Local Slurm instances are per-project, so the number of concurrent secure jobs scales with the number of projects and the available hardware. The tiCrypt backend coordinates VM lifecycle across all projects.
- Dual Slurm architecture separates resource allocation (Global Slurm) from secure job execution (Local Slurm). Global Slurm never sees job content, scripts, or data.
- End-to-end encryption with public-key authentication ensures that the infrastructure, including system administrators, cannot access user data. Private keys never leave the user's device.
- Each job runs in its own ephemeral VM with an encrypted drive. When the job finishes, the VM is destroyed and the encryption key is discarded.
- No OS user accounts are needed on cluster nodes: Users authenticate with digital signatures, eliminating password-based attack vectors.
- Standard Slurm commands work unchanged: Researchers use
sbatch,srun,squeue, andsacctwithout modification. - Bare-metal container support is in development for MPI workloads that require native network performance and cannot tolerate virtualization overhead.